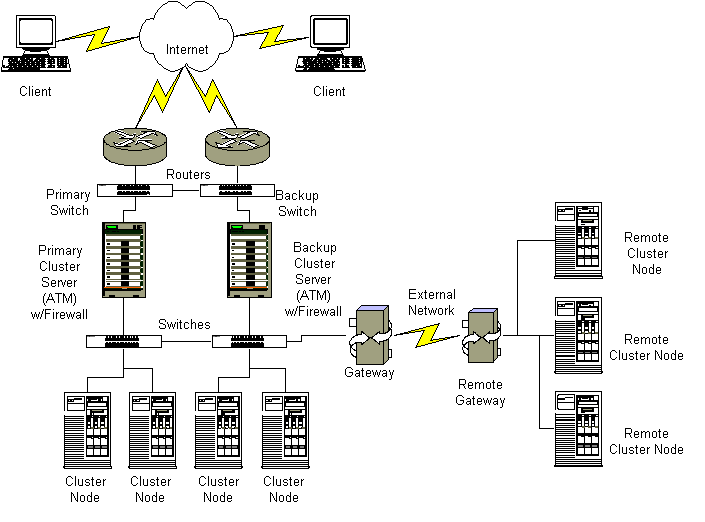
Advanced Traffic Manager (ATM)
ATM performs the task to direct
all incoming requests to cluster server which has
the highest availability. The present version of
ATM runs on Linux 2.2 or above. i-cluster Server
running on Windows NT, 2000 server, 95/98 will be
released soon. In case of down of ATM, backup ATM
will take place and there is virtually no limitation
on number of backup ATM stations. Backup ATM stations
will synchronize with ATM station in customizable
time of frequency.
Unlimited
cluster nodes
No limitations on no. of cluster
nodes and ATMs.
Platform
independent cluster server
Cluster server can run
on different platform, such as Linux, Windows 95/98/NT/2000,
UNIX, Novell (running TCP/IP). Like ATM, there is
virtually no limitation on number of cluster nodes.
No software required for running as a cluster server.
Integrated
Firewall Option
Prevents intrusion attack
from external as well as internal network.
Virtually
any port can cluster
No pre-defined requirement
of service ports, meaning any port can cluster.
|
Adjustable Load Balancing
Pattern
This feature allow administrators
to put more load on servers with higher processing
power and less load on servers with less processing
power.
Stand-by
servers
In case all cluster servers
went down, stand-by server will assume service automatically.
This stand-by server can be located anywhere connected
via internet and contents might differ from cluster
servers. This might be set up to, for instance display
contingency messages in case of server failure.
Email
notification
In case of failure of any
server in the cluster network, local or remote,
administrator will be notified by email or pager.
System
Requirements
- Intel x86 architecture CPU,
including Intel, AMD, and Cyrix models
- 32Mb RAM (128Mb recommended)
- 800Mb hard disk space
- 2 x PCI Ethernet Network adaptor
- 3.5-inch floppy drive
United
Networks Inc.
www.unitednet.com.hk
enquiry@unitednet.com.hk
|
|
IBM
Cluster Systems Management for Linux (CSM),General Parallel
File System (GPFS)
|
Kimberlite |
ATM |
| Nodes |
32 nodes |
No limit |
No limit |
| User Interface |
GUI management
interface. |
Command
and web management interface. |
Command
line and web management interface. |
| Node
- Recovery |
Admin
may reset or power switch node at remote location. Limited
to IBM hardware only. |
User
implement own power switch and UPS. Serial cable hooked
up with peer systems allows peer monitoring and reset/power-cycle.
(Called "Service Failover") |
Not yet
available. May implement techniques similar to Kimberlite.Recommendation:
Node failover could be handled gracefully, with another
server taking over the work of the failed server and making
sure the integrity of data being processed on the failed
node. Working nodes should recover failed node immediately.
This is especially important on database servers. Be able
to commit/reset/recover transactions or requests on failed
node. Task could be simplified with the use of a distributed
fault-tolerant filesystem (CODA).In order to minimize
the disruption done to the Cluster/Node, ATM server monitoring
the failed node should attempt to restart only the failed
service, resorting to the entire server when this step
fails. |
| Node
- Monitoring |
Centralised
control from Server (as oppose to Node). Uses a common
storage area for keeping node heartbeat and status information. |
No centralized
control. Uses peer monitoring among Nodes insteadUses
common storage to keep node status. Peers probe each other
as well as actively updating own status in shared memory
(Quorum). A node is deemed failed when it fails either
response to a statue probe, or fails to write status to
shared memory. |
Centralised
control. Server (or Backup Server) keeps track of the
node status (Heartbeat Ping). Cluster nodes therefore
are relieved from the task of probing each other. Thus
reducing traffic on the network.Heartbeat ping implemented
using ICMP. Implementing Node Service monitoring, which
defines the specific port number to monitor in a Node.
|
| Node
- Maintenance |
Administration
and maintenance of node can be done remotely. Also has
an option of combining output from multiple nodes. |
|
Because
ATM do not use client program on Node, obtaining accurate
performance figures and remotely configuring nodes may
be difficult. This can be resolve through other means
such as providing telnet or remote configuration program.On
the plus side. By not placing a client on the Node this
practice simplifies the system design and reduce the amount
of traffic. |
| Server
- Configuration |
Only
centralized control and one form of cluster set up. One
server per cluster, containing multiple nodes. |
Can be
implemented in several configurations. Such as active
peer monitoring configuration where each Node runs different
services and each Node keeps track of other and services.
Or the primary/backup configuration where when a primary
Node fails, the secondary/backup Node becomes active and
automatically takes over the service. |
Users
centralized monitoring with backup node when primary servers
failed (called "fallback", or be implemented.Could make
use a voting system between ATM servers and a shared common
area (quorum) when one server fails. Also, to prevent
the primary server becoming a bottleneck a DNS rotation
scheme can be implemented to make proper use of the backup
ATM servers. |
| Server
- Monitoring |
Unknown |
Uses heartbeat
ping between peer servers/nodes, also use Quorum to detect
non-behaving servers. |
ATM servers
use peer monitoring ATM primary and backup servers. Data
synchronization also happens at this point. |
| Error
Logging |
Logging/Output
to a common output (Distributed Shell) |
Uses syslog
with severity level |
Log file
per Node and each ATM server. |
| Scheduling
& Load Balancing |
No information |
No information |
Task
scheduling in a weighted round-robin fashion. When a certain
node fails request is automatically passed on to the next
available node, with regards to the node weighting/priority. |
| OS Implementation |
Linux,
AIX |
Node systems
using same OS (linux) |
Node systems
are free to use any OS. OS independent as no client software
on a Node are necessary. |
| File
System & Storage |
Can deploy
propriety file system: General Parallel File System (GPFS).
Features: Block level locking, Data Stripping along several
drives. |
No filesystem
information. Hardware recommendation based on SCSI RAID
drives with partition locking. |
SAN (Hardware
solution). Recommended also making CODA filesystem (Software
solution) part of the software, which is widely available
and the CODA driver is part of a regular kernel. However,
simultaneous access (bad) may need some work. |